
本記事では、Pythonのライブラリであるscikit-learn (sklearn)を使用して、誰でも簡単に回帰分析をPythonで実装する方法をご紹介します。単回帰・重回帰問わず、データフレームから回帰分析の流れで一発で実装可能です。
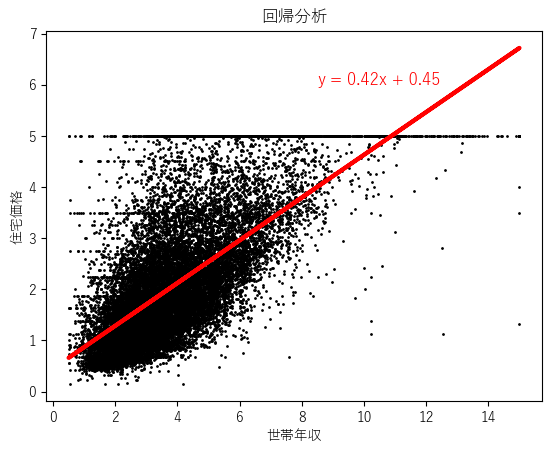
結論
Pythonでの回帰分析は下記のコードで実装可能です。カリフォルニアの住宅価格のデータセットを使用しています。なお、今回の分析では単回帰となっていますが、重回帰分析の際にはカラムを複数指定した上でそのまま同じコードで実装可能です。
以降のセクションでステップごとに丁寧に解説します。
# ライブラリのインポート
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_california_housing
# データセットの読み込み
data = fetch_california_housing()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['MedHouseVal'] = pd.Series(data.target)
# 説明変数と目的変数の定義
X = df[['MedInc']]
y = df['MedHouseVal']
# モデルの作成とフィット
model = LinearRegression()
model.fit(X, y)
# グラフの描画
plt.scatter(X, y, color='black', s=1)
plt.plot(X, model.predict(X), color='red', linewidth=3)
plt.rc('font', family='Yu Gothic')
plt.xlabel('世帯年収')
plt.ylabel('住宅価格')
plt.title('回帰分析')
plt.show()前提: 回帰分析とは
回帰分析とは、ある事象Y(例:テストの点数)が別の事象X(例:勉強時間)にどのように影響されるかを調べるための分析手法です。簡単に言うと、「勉強時間が長いほど、テストの点数は高くなるのか?どの程度高くなるのか?」というような関係を数学的に分析します。
より詳しい概要や分析イメージの解説は下記の記事にて行っています。

Pythonで回帰分析を行うステップ (単回帰・重回帰共通)
概要
Pythonでscikit-learn (sklearn) を使用して回帰分析を実装するステップは下記のとおりです。単回帰・重回帰共通して同じステップで実装可能なため、説明変数の数に合わせてXに代入する際のカラム数を調整してください。
なお、クリックで該当セクションにジャンプします。
- ステップ1
- ステップ2
- ステップ3
- ステップ4
- ステップ5
- 補足
具体的なステップ
必要なライブラリのインポート
まず、必要なライブラリをインポートします。これらのライブラリがインストールできていない方は、併せてpip install {ライブラリ名}を実行してください。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_california_housingデータセットの読み込み
カリフォルニアの住宅データセットを読み込みます。scikit-learn (sklearn) には複数のサンプルデータセットがありますので興味がある方は公式ドキュメントを確認してみてください。
読み込みデータに関してはご使用のものに置き換えて、df = 使用したいデータとなるようにしてください。
data = fetch_california_housing()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['MedHouseVal'] = pd.Series(data.target)
説明変数と目的変数の定義
説明変数(世帯年収)と目的変数(住宅価格)を選択します。今回は単回帰となっていますが、重回帰 (説明変数が2つ以上) の場合はカラムを複数指定してください。
X = df[['MedInc']] # `df['MedInc'].values.reshape(-1, 1)`と同じ用途
y = df['MedHouseVal']線形回帰モデルの作成とフィット
LinearRegressionクラスを使用して線形回帰モデルを作成し、すべてのデータでモデルをフィットします。
model = LinearRegression()
model.fit(X, y)結果の可視化
最後に、実際の値と予測値をプロットして、モデルのパフォーマンスを視覚的に評価します。
plt.scatter(X, y, color='black', s=1)
plt.plot(X, model.predict(X), color='red', linewidth=3)
plt.rc('font', family='Yu Gothic')
plt.xlabel('世帯年収')
plt.ylabel('住宅価格')
plt.title('回帰分析')
plt.show()(補足) 結果の抽出
回帰係数、切片、および R²(決定係数)などの分析結果を出力するためには、以下のコードを実行します。その他、LinerRegressionに関する詳細は公式ドキュメントをご確認ください。
from sklearn.metrics import r2_score
print(model.coef_[0]) # 回帰係数 (リストで出力される)
print(model.intercept_) # 切片
print(r2_score(y, y_pred)) # R²値おわりに
以上がPythonで回帰分析を行う方法のご紹介になります。簡単かつ迅速に実装できるため、データ分析で非常に重宝します。
ご質問やご不明点がある場合はお気軽にコメントお待ちしております。
ご精読いただきありがとうございました。


コメント